ORM
简介
ORM(Object-Relational Mapping)是一种将关系型数据库中的数据表映射为面向对象编程语言中的类和对象的技术。它允许开发者使用面向对象的方式来操作数据库,而不需要直接编写 SQL 语句。
如果不使用 ORM,我们需要手动操作把数据库的行数据映射成对象,耗时且重复:
sql = "SELECT * FROM product"
result = cursor.execute(sql)
for row in result:
product = Product()
product.title = row[1]
product.price = row[2]
# 其他字段...
而使用 ORM 后,我们可以直接通过类和对象来操作数据库:
products = Product.objects.all()
for product in products:
print(product.title, product.price)
但这并不意味着 ORM 是万能的,在某些复杂查询或性能要求较高的场景下,直接编写 SQL 可能更高效。因此,了解 ORM 的原理和使用场景非常重要。总体来说,ORM:
- 降低代码的复杂性,使其更易读和维护
- 提高开发效率,减少重复代码
过早的优化是万恶之源,先使用 ORM 来快速开发和迭代,等到性能成为瓶颈时再考虑直接编写 SQL 来优化特定查询。
Django 的 迁移(migration)就是很好的例子,我们执行迁移后,这些表格和字段的创建、修改等操作通过 ORM 来即刻实现,我们不需要关心底层 SQL 如何执行。实际上,迁移也是 ORM 的一部分。
也许你可能也注意到了,现有的数据模型都是通过继承 Django 的 models.Model 来定义的,这也是 ORM 的核心设计之一。通过继承 models.Model,我们可以利用 Django 提供的各种字段类型、查询接口和迁移工具来管理数据库中的数据模型。
管理器(manager)和查询集(queryset)
让我们回到 playground/views.py 中,删除无用代码并添加:
from django.shortcuts import render
from django.http import HttpResponse
from store.models import Product
def say_hello(request):
query_set = Product.objects.all()
return render(request, 'hello.html', {
'name': 'Today Red',
})
每个数据模型类都会有一个名为 objects的属性。以 Product 为例,Product.objects 返回了一个管理器对象。管理器是数据库的接口,能让我们与数据库进行通信和操作。我们可以看到 Product.objects 下有很多查询和更新数据的方法,如 all()、filter()、get() 等等。
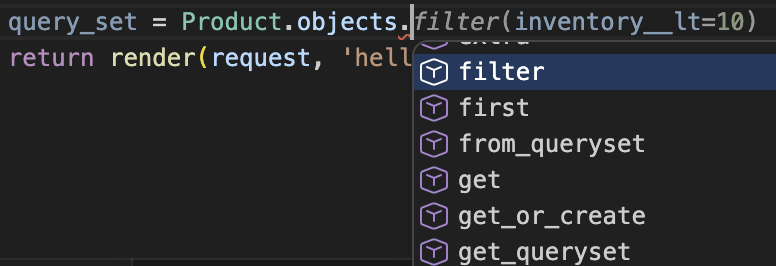
这些方法返回的结果通常是一个查询集(queryset),查询集是封装查询的对象.
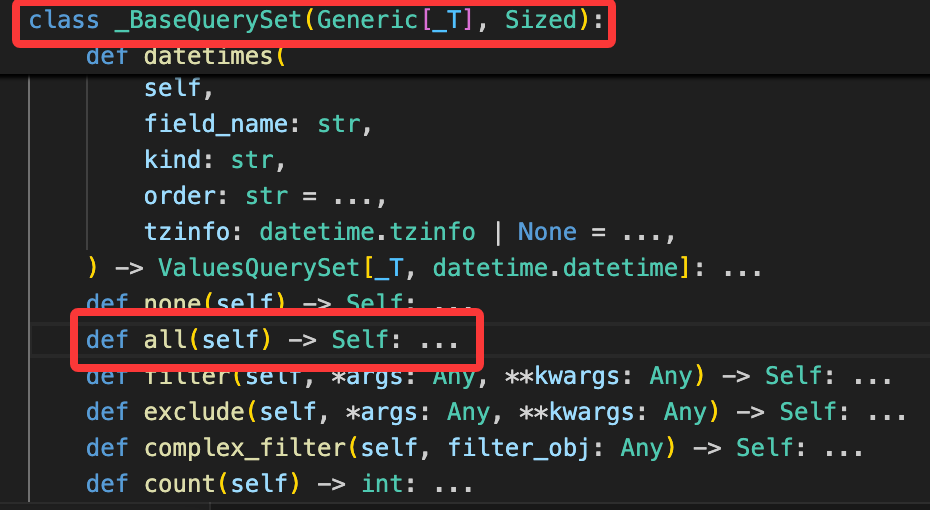
在特定条件下 Django 会计算这个查询集,此时 Django 会生成正确的 SQL 语句并发送到数据库。这里的特定条件主要是三种情况:迭代查询集、将查询集转换为列表、访问查询集的某个元素。
迭代查询集
更新 playground/views.py 中的 say_hello 视图函数:
def say_hello(request):
query_set = Product.objects.all()
for product in query_set:
print(product.title, product.unit_price)
return render(request, 'hello.html', {
'name': 'Today Red',
})
我们保存并刷新浏览器页面,点击右侧的 SQL 选项卡,可以看到 SQL 语句 执行情况:
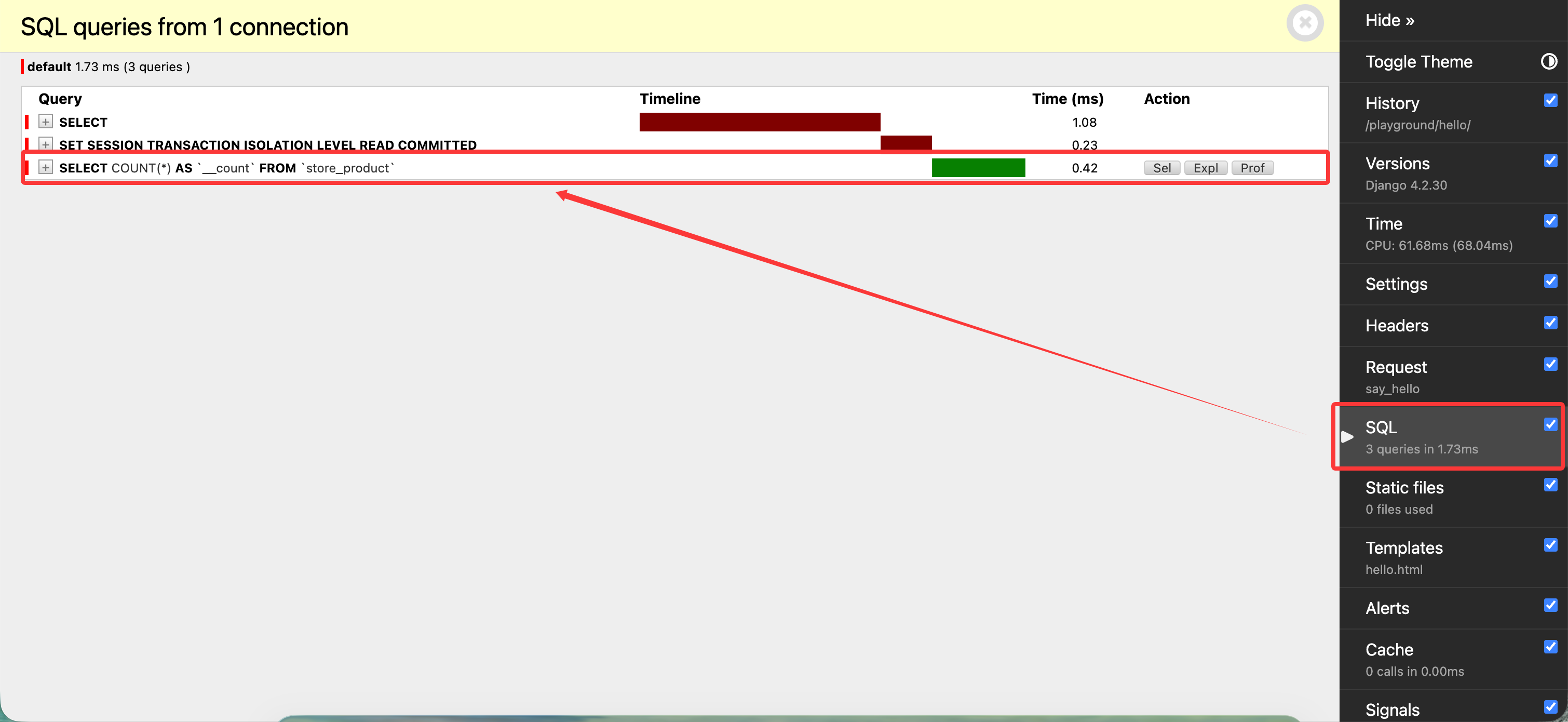
点击 seql 选项卡,我们可以看到 Django 生成的 SQL 语句:
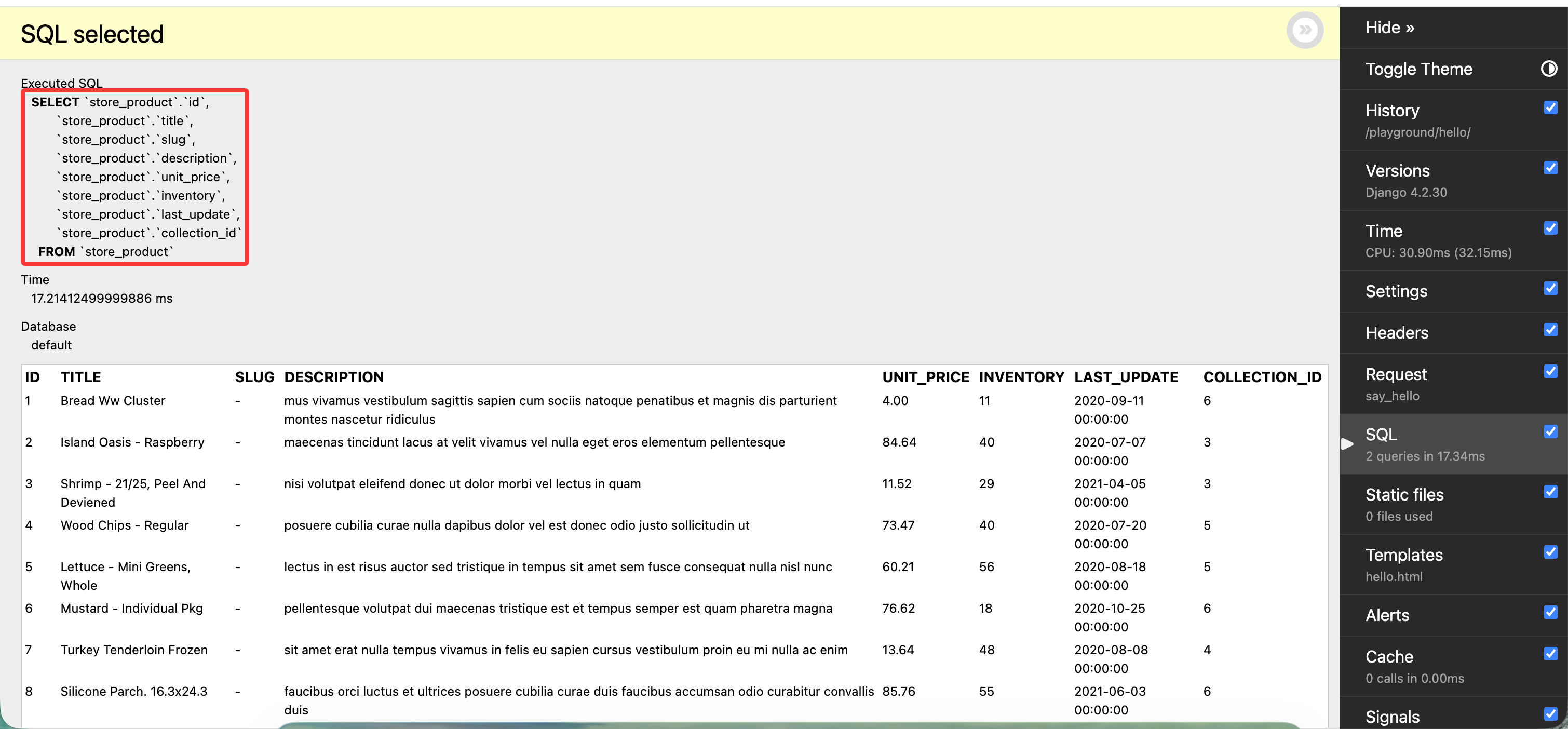
将查询集转换为列表
更新 playground/views.py 中的 say_hello 视图函数:
def say_hello(request):
query_set = Product.objects.all()
for product in query_set:
print(product.title, product.unit_price)
list(query_set)
return render(request, 'hello.html', {
'name': 'Today Red',
})
保存并刷新浏览器页面,点击右侧的 SQL 选项卡,同样可以看到 SQL 语句 执行情况。
访问查询集的某个元素
更新 playground/views.py 中的 say_hello 视图函数:
def say_hello(request):
query_set = Product.objects.all()
list(query_set)
print(query_set[0: 5])
return render(request, 'hello.html', {
'name': 'Today Red',
})
保存并刷新浏览器页面,点击右侧的 SQL 选项卡,同样可以看到 SQL 语句 执行情况。
事实上我们还可以在返回的查询集上继续调用其他方法来构建更复杂的查询,例如:
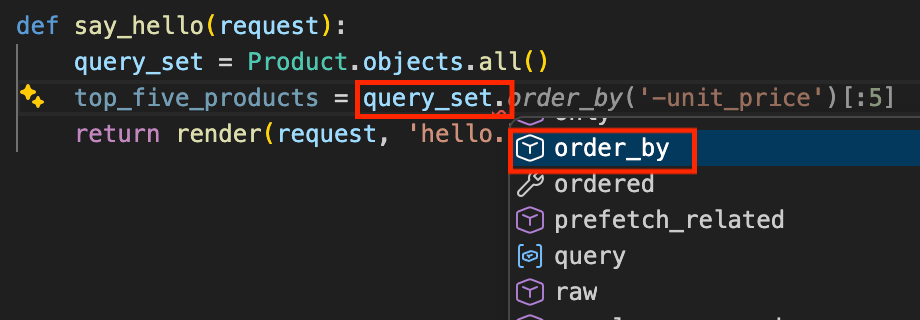
从上面的例子我们不难发现查询集是一个惰性对象,只有在特定条件下才会被计算并生成 SQL 语句发送到数据库。这种设计使得我们可以链式调用查询集的方法来构建复杂的查询,而不需要担心性能问题,因为只有在真正需要数据的时候才会执行查询。
当然,并不是所有的方法都会返回查询集,例如 count() 方法会直接返回一个整数,表示查询集中的对象数量,而不是返回一个新的查询集。
检索对象
这一节我们将讨论不同的检索对象,首先第一个是我们已经使用过的 all() 方法,它返回一个包含所有对象的查询集:
query_set = Product.objects.all()
有时我们可能只需要查询集中的单一对象,这时可以使用 get() 方法,get() 方法会根据提供的条件来检索并返回单一对象,而不是查询集:
def say_hello(request):
print(query_set[0: 5])
product = Product.objects.get(id=1)
return render(request, 'hello.html', {
'name': 'Today Red',
})
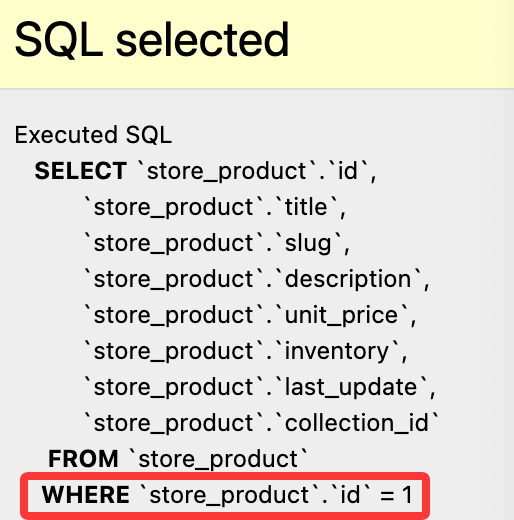
get() 方法可以接受一个特殊参数 pk,它是主键的缩写,等价于表中的主键,让我们免于记忆主键的名称。在 Product 表中等价于 id 字段。保存并刷新浏览器页面,点击右侧的 SQL 选项卡,可以看到 SQL 语句 执行情况:
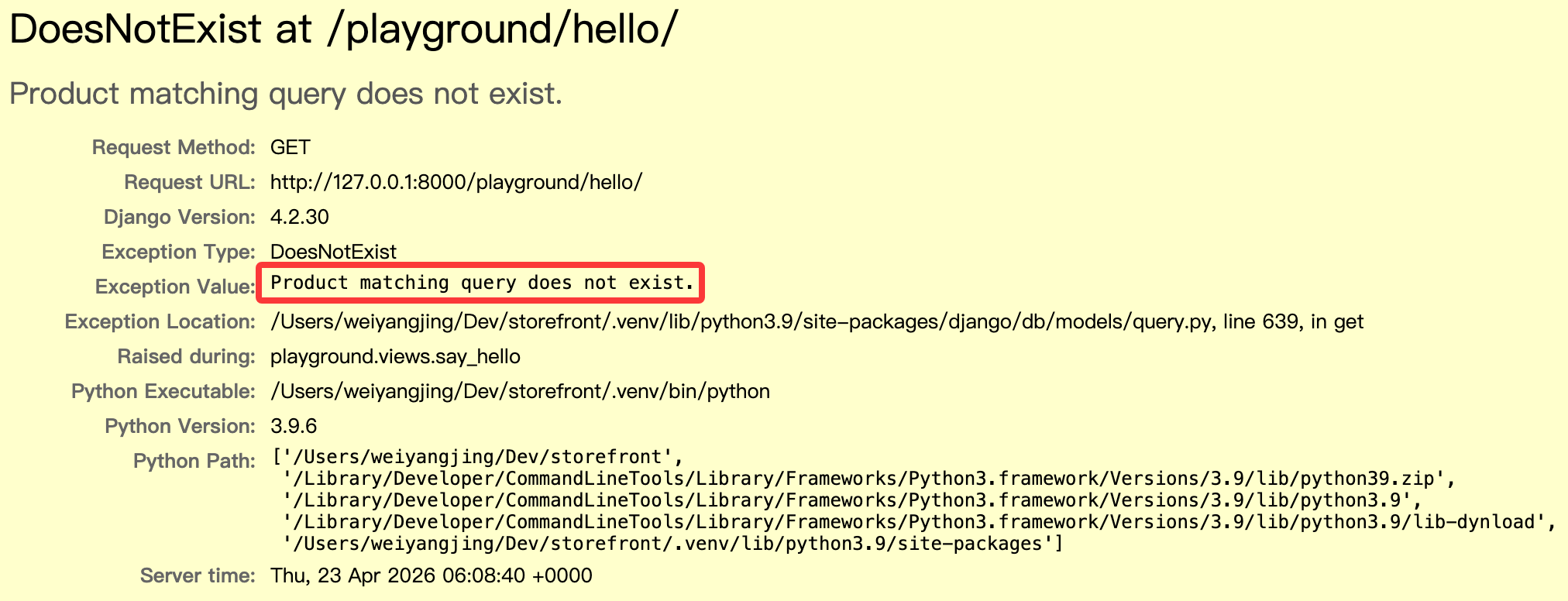
如果我们用 get() 方法来查询一个不存在的对象,或者查询到多个对象,Django 会抛出异常:
def say_hello(request):
product = Product.objects.get(id=1)
product = Product.objects.get(id=0)
return render(request, 'hello.html', {
'name': 'Today Red',
})
那么在代码中,我们应当使用 try-except 块来捕获这些异常:
from django.shortcuts import render
from django.core.exceptions import ObjectDoesNotExist
from store.models import Product
def say_hello(request):
product = Product.objects.get(id=0)
try:
product = Product.objects.get(id=0)
except ObjectDoesNotExist:
print("Product does not exist")
return render(request, 'hello.html', {
'name': 'Today Red',
})
此时我们就可以安全地处理查询不到对象的情况了。只是这样处理非常麻烦,我们可以使用 filter() 方法来替代 get() 方法,filter() 方法会返回一个查询集,如果没有对象满足条件,则返回一个空的查询集:
product = Product.objects.filter(id=0)
如果我们想要获取满足条件的第一个对象,可以使用 first() 方法:
product = Product.objects.filter(id=0).first()
如果我们想要判断查询集是否为空,可以使用 exists() 方法:
exists = Product.objects.filter(id=0).exists()
此时 exists 将会是一个布尔值,表示是否存在满足条件的对象。